Performance Engineering: Series-II

How to improve Throughput of a Service?
Just to recap, Throuhput is measured as the number of requests an app can handle in a second without compromising on the latency sla. Before we go deep into how to improve the performance let's look at the flow in a typical web service. Most of the webservices, pull data from a data store, then processes it and serves it as part of the response. Serialization is involved in reading the request and serving the resopnse back. To understand better, let's take a look at how a single request flows through.
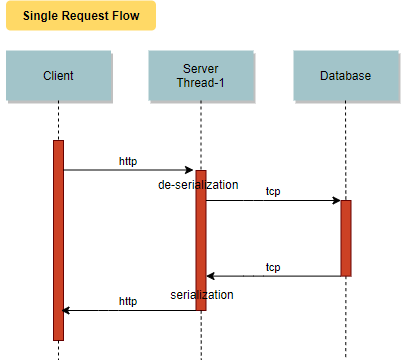
The request lands on a worker thread from the server's thread pool. This thread de-serializes the request and makes a database call to load the required data. Until the database server responds, the thread is blocked (blocked state & not runnable). Similarly, the client is blocked until the response is provided by the server. Now let's take a look at a multi-request flow.
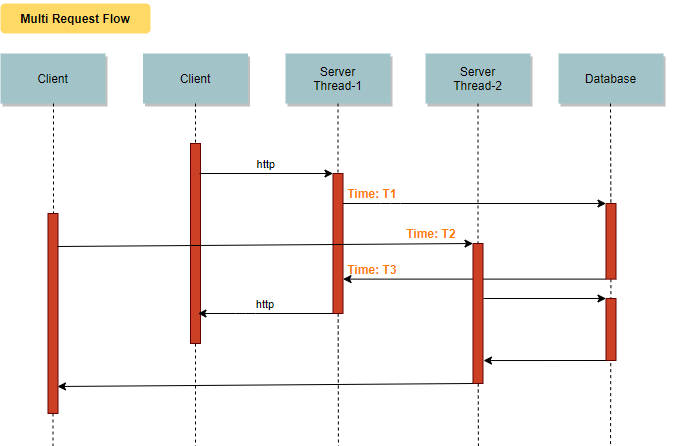
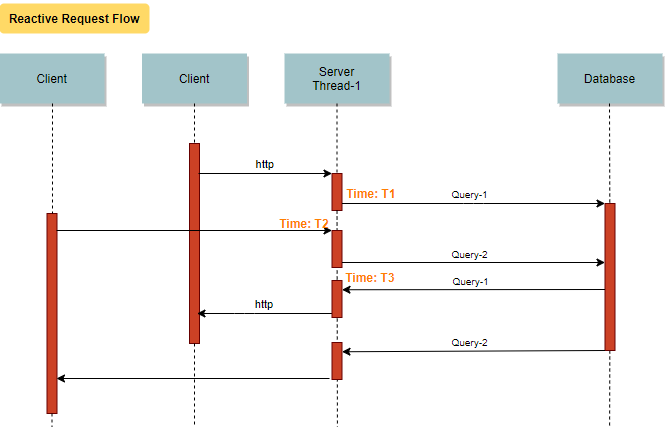
If you observe the above flow carefully, you would notice that "server thread-1" goes into a blocked state from time T1 till T3. So a new request comes at time T2, it had to be handles by another worker "sever thread-2". This would mean that the kernel has to perform a thread context switch from "server thread-1" to "server thread-2". Context switching between kernel threads requires saving the value of the CPU registers from the thread being switched out and restoring the CPU registers of the new thread being scheduled, which is a costly operation (cpu cycles are lost here). Now imagine the cycles lost when a webserver that has hundreds of threads is handling incoming requests. Is there was a mechanism to avoid a thread context switch or keep it minimal?
Enter the world of Reactive Programming!!
Reactive programming is non-blocking and can be achieved in any of the below ways:
- Futures/Promises
- Dataflow Programming - Shared Memory
- Reactive Streams
- Tokio - in Rust
- Quarkus - uses netty & vert.x
- NodeJs
- Co-routines in GoLang & Kotlin
- Akka - uses actors
What is the benefit of making a legacy/existing system reactive?
When building a new System, it could be built using a reactive methodology. But what is the incentive in modifying an existing app? Given that most of the services are now deployed on cloud, making an existng system reactive would result in more throughput per host/pod. This translates directly to cutting the cost to half or less depeding on the use-case. If the development budget is less, you could still make use of reactive methodology for the core service being handling by your team. Quarkus is one such frameowork that makes it easier to port your application wwithout a major rewrite.
Follow me on LinkedIn or Bookmark this site to get more updates on this blog. Please leave your feedback in the comments section on any improvements.